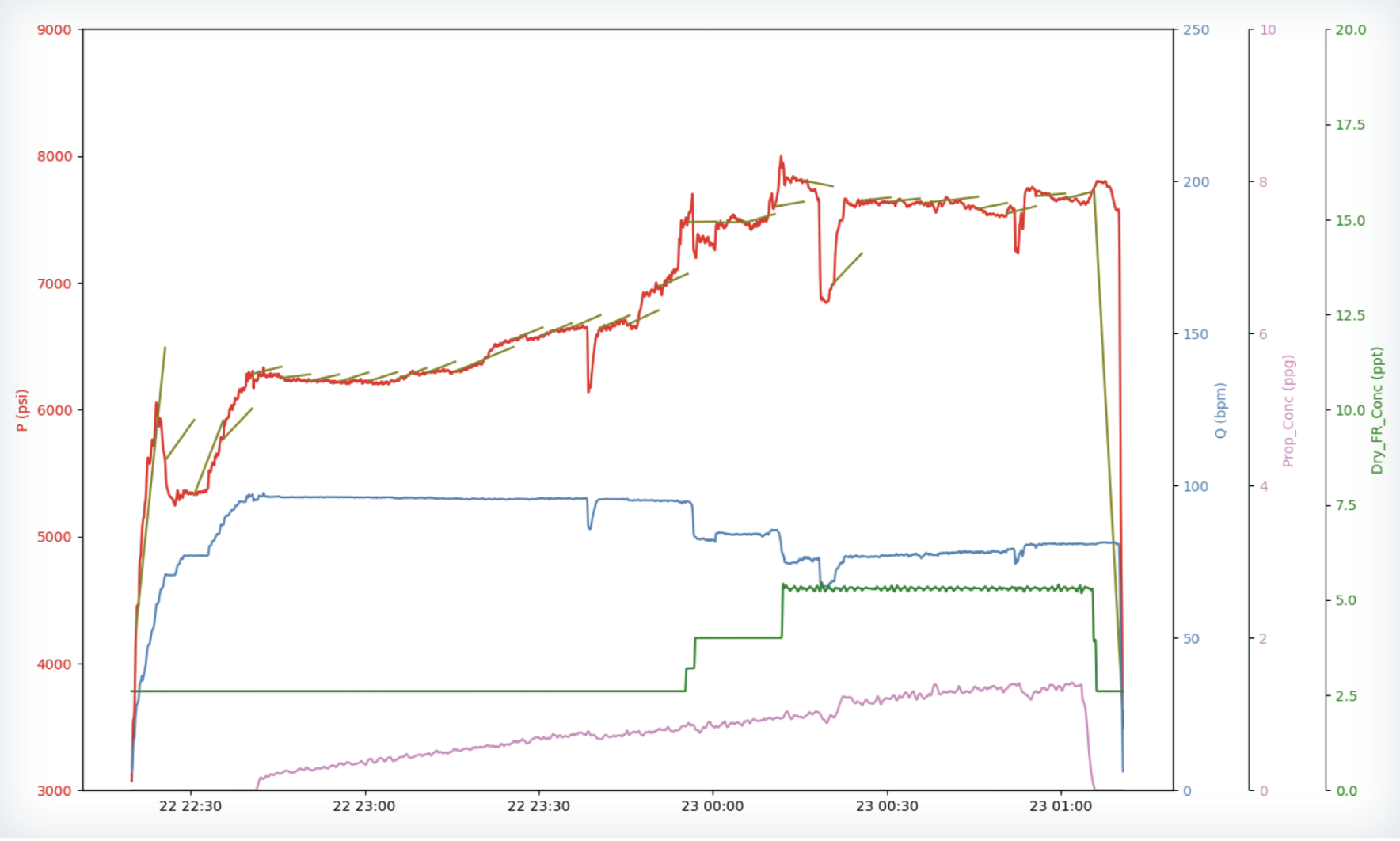
Liberty Energy公司利用两个非常规油气盆地完成的1500个压裂段的数据训练了深度学习模型。在预测中,该模型准确预测了整个压裂段压力上升的趋势。图中,红线表示实际压力,橄榄绿线(红线旁边)表示模型预测的给定时间段(通常为五分钟间隔)内的压力变化。蓝线表示压裂液的注入速率,绿线表示减阻剂浓度,紫线表示支撑剂浓度。来源:SPE 230658
Deep learning model under development to predict frac treating pressures in real time
Once completed, model could serve as basis of automated workflows, optimized pump rate schedules to further scale frac operations
Mar 4, 2026
0 28 4 minutes read
Liberty Energy trained the deep learning model on 1,500 stages completed in two unconventional basins. In this prediction, the model correctly predicted the trend of rising pressures throughout the stage. In this graph, the actual pressure is indicated by the red line, while the olive green lines (next to the red line) represent the model’s predicted changes in pressure over a given time frame (typically five-minute intervals). The blue line is the injection rate of the frac fluid, the green line is the friction reducer concentration, and the purple line is the proppant concentration. Source: SPE 230658
By Stephen Whitfield, Senior Editor
Hydraulic fracturing in unconventional plays has scaled into an industrial process, with the number of stages being completed in each well higher than ever before. To boost the operational efficiencies that make scaling frac possible, the industry is now turning more and more to automation. Specifically, the industry is looking at how automation can be leveraged to optimize rate schedules and pumping stages, thereby streamlining the frac design process.
Karn Agarwal, Senior Staff Engineer – Data Science at Liberty Energy, said this type of automation can allow operators to bring wells into production faster and complete more wells per year. However, to turn this into reality, the industry needs reliable models that can forecast and predict treating pressures far enough into the future.
At the 2026 SPE Hydraulic Fracturing Technology Conference in The Woodlands, Texas, on 5 February, Mr Agarwal discussed the development and training of a deep learning model designed to forecast surface treating pressures. The model uses a variety of inputs, including time series data for past treatments and future treatment design. It can incorporate stage-level completion details, as well as rock property data from logs and drilling data.
“We want to combine multiple inputs and generate something that can be trained on very large amounts of frac treatment data in this neural network architecture,” Mr Agarwal said. “It’s analogous to large language models, which, in essence, take a sequence of words or tokens and try to predict the next word or token in the sequence. In that sense, surface pressure responses, or the reactions of the rock during the frac job, that’s the language of this equipment, and the sequence we’re predicting is a time sequence.”
The final goal with the model, when completed, is to use it to develop a reliable real-time pressure forecasting tool that could capture nuances and events that a human treatment supervisor may not readily recognize.
Mr Agarwal outlined several potential applications of the model. For one, it could be used to detect rising treating pressures or screenouts in advance. This could be done as either a classification (predicting if a screenout will occur given a window of treating data and a future design) or as a regression. The model could also be deployed in real-time applications, where it could make a prediction as often as needed, or it could serve as a foundational model for automation workflows optimizing pump rate schedules.
Training on 1,500 stages of data
The model was trained and tested in 2025 on a data set of 1,500 stages completed in two unnamed unconventional basins. Prior to testing the deep learning model, the researchers ran a separate, traditional machine learning model that served as the benchmark for minimum model performance. This model used the same data as the deep learning model, but it did not feature the multilayered artificial neural networks that automatically learn patterns from the data.
The training root mean squared error (RMSE) for the pressure estimations, or the deviation of the predicted values from the actual values in each stage, was 390 psi. For the deep learning model, the RMSE was 280 psi, indicating that the deep learning model would have a lower relative uncertainty in its predictions compared with the benchmark.
This lower relative uncertainty manifested at points during the testing. For example, in one test stage, the slurry rate appeared to be the dominant feature affecting the pressure response. The model predicted a sudden rate drop and a rise in pressure during the rate ramp-up period, and it determined a rise in surface treating pressures during a flush (when the surface proppant concentration drops to zero) due to a decrease in hydrostatic pressure. These predictions, which were made solely through analyzing the test data set, lined up with the expectations of the research team.
“You could see with this test that the model was learning to predict the rise in treating pressures during the ramp-up period, and it predicted it fairly well,” he said. “It also learned to predict the rise in pressure during the flush, and it was all done in a data-driven manner. We weren’t telling the model anything. That’s very encouraging to see the model predict these effects,” Mr Agarwal said.
Where the model struggled in testing was in the period between the ramp-up and the shut-in. Mr Agarwal said the model had trouble keeping its predictions within the RMSE because the slurry rate is mostly constant during this period. Because of that, the model had difficulty learning from unforeseen treating pressure changes caused by effects in the formation – these types of changes, he said, do not occur as frequently in this period.
“Sometimes the model lost its footing in this period. If we had any abrupt pressure changes due to a downhole effect – say, a frac or a cluster gets blocked, or a new cluster opens – the model will have a hard time predicting because it’s working off of a limited range of inputs,” he said.
The data set used in the test did not contain any stages that screened out, but Mr Agarwal noted that there were some stages where the treating pressures were close to working pressure limits.
In one example stage, pressures rose throughout the stage and got close to working pressure limits toward the end of the stage. In that instance, the model predicted the correct trend by consistently forecasting a rise in pressure once the design rate was achieved. However, while it could show the trend of continuously rising pressure increases, it could not predict the size of the pressure increase – Mr Agarwal said this was likely because the model underestimated the friction reducer concentrations needed in this stage. Future work on the model will explore how the model’s performance can be improved in this type of situation.
Other future work on the model will focus on incorporating larger data sets and log data, as well as ensuring better quality control of raw data. DC
For more information, please see SPE 230658, “Using Deep Learning to Forecast Fracture Treating Pressures in Real Time.”